Zettascale chez Oracle
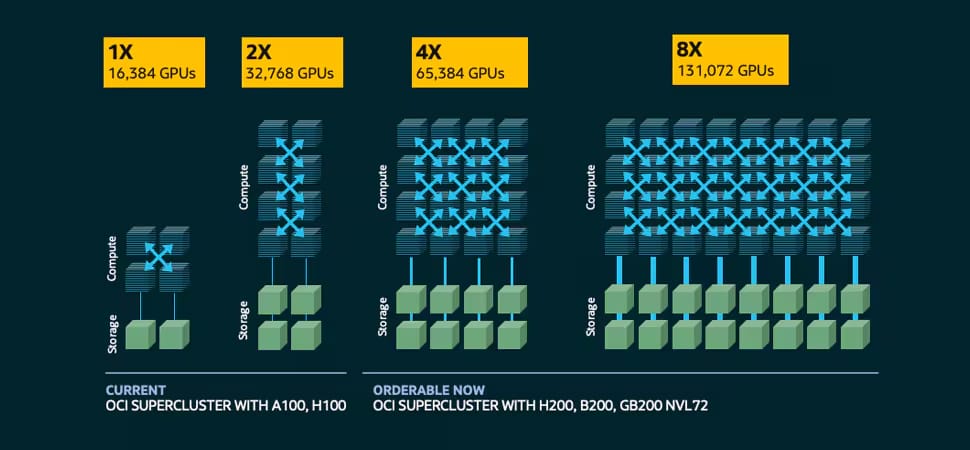
Durant la conférence CloudWorld 2024, Oracle a dévoilé son supercalculateur zettascale utilisant l'architecture Blackwell de NVIDIA. Oracle annonce jusqu'à 131 072 GPU NVIDIA en ligne dédiés à l'IA / LLM. En puissance de calculs, l'éditeur annonce 2,4 zettaflops. OCI Supercluster inclut Compute Bare Metal et des connectiques réseaux NVIDIA Quantum-2 InfiniBand.
Les superclusters OCI peuvent être commandés avec OCI Compute optimisé par des GPU NVIDIA H100 ou Tensor Core H200 ou NVIDIA Blackwell. Les superclusters OCI avec des GPU H100 peuvent atteindre 16 384 GPU avec jusqu’à 65 ExaFLOPS de performances et 13 Po/s de débit réseau agrégé. Les superclusters OCI avec des GPU H200 atteindront 65 536 GPU avec jusqu’à 260 ExaFLOPS de performances et 52 Po/s de débit réseau agrégé et seront disponibles plus tard cette année. Les superclusters OCI dotés d’instances bare metal refroidies par liquide NVIDIA GB200 NVL72 utiliseront NVLink et les commutateurs NVLink pour permettre à jusqu’à 72 GPU Blackwell de communiquer entre eux avec une bande passante agrégée de 129,6 To/s dans un domaine NVLink unique.
« Nous disposons de l’une des offres d’infrastructure d’IA les plus étendues et prenons en charge les clients qui exécutent certains des workloads d’IA les plus exigeants dans le cloud », explique Mahesh Thiagarajan, executive vice president, Oracle Cloud Infrastructure. « Avec le cloud distribué d’Oracle, les clients ont la flexibilité de déployer des services cloud et d’IA où qu’ils se trouvent, tout en préservant les plus hauts niveaux de souveraineté des données et de l’IA. »
avec à la clé une performance sans OCI Supercluster inclut OCI Compute Bare Metal, une latence ultra-faible RoCEv2 avec des cartes d’interface réseau ConnectX-7 et ConnectX-8 SuperNICs ou la plate-forme réseau NVIDIA Quantum-2 InfiniBand, ainsi qu’un choix de stockage HPC. Les GPU NVIDIA Blackwell, disponibles au premier semestre 2025, avec NVLink de cinquième génération, le commutateur NVLink et la mise en réseau de cluster, permettront une communication transparente de GPU à GPU au sein d’un seul cluster.